BeanHub Import
Beanhub-import is a simple, declarative, smart, and easy-to-use library for importing extracted transactions from beanhub-extract. It generates Beancount transactions based on predefined rules.
Please also checkout our blog posts about the BeanHub Import, BeanHub Connect and BeanHub Direct Connect features:
- BeanHub Import - One small step closer to fully automating transaction importing
- BeanHub Connect - one giant leap with fully automatic bank transactions import from 12,000+ financial institutions in 17 countries for all Beancount users!
- Direct Connect: Pulling transactions as CSV files from banks via Plaid directly
Features
- Easy-to-use - you only need to know a little bit about YAML and Jinja2 template syntax.
- Simple declarative rules - A single import file for all imports
- Idempotent - As long as the input data and rules are the same, the Beancount files will be the same.
- Auto-update existing transactions - When you update the rules or data, corresponding Beancount transactions will be updated automatically.
- Auto-move transactions to a different file - When you change the rules to output the transactions to a different file, it will automatically remove the old ones and add the new ones for you
- Merge data from multiple files (coming soon) - You can define rules to match transactions from multiple sources for generating your transactions
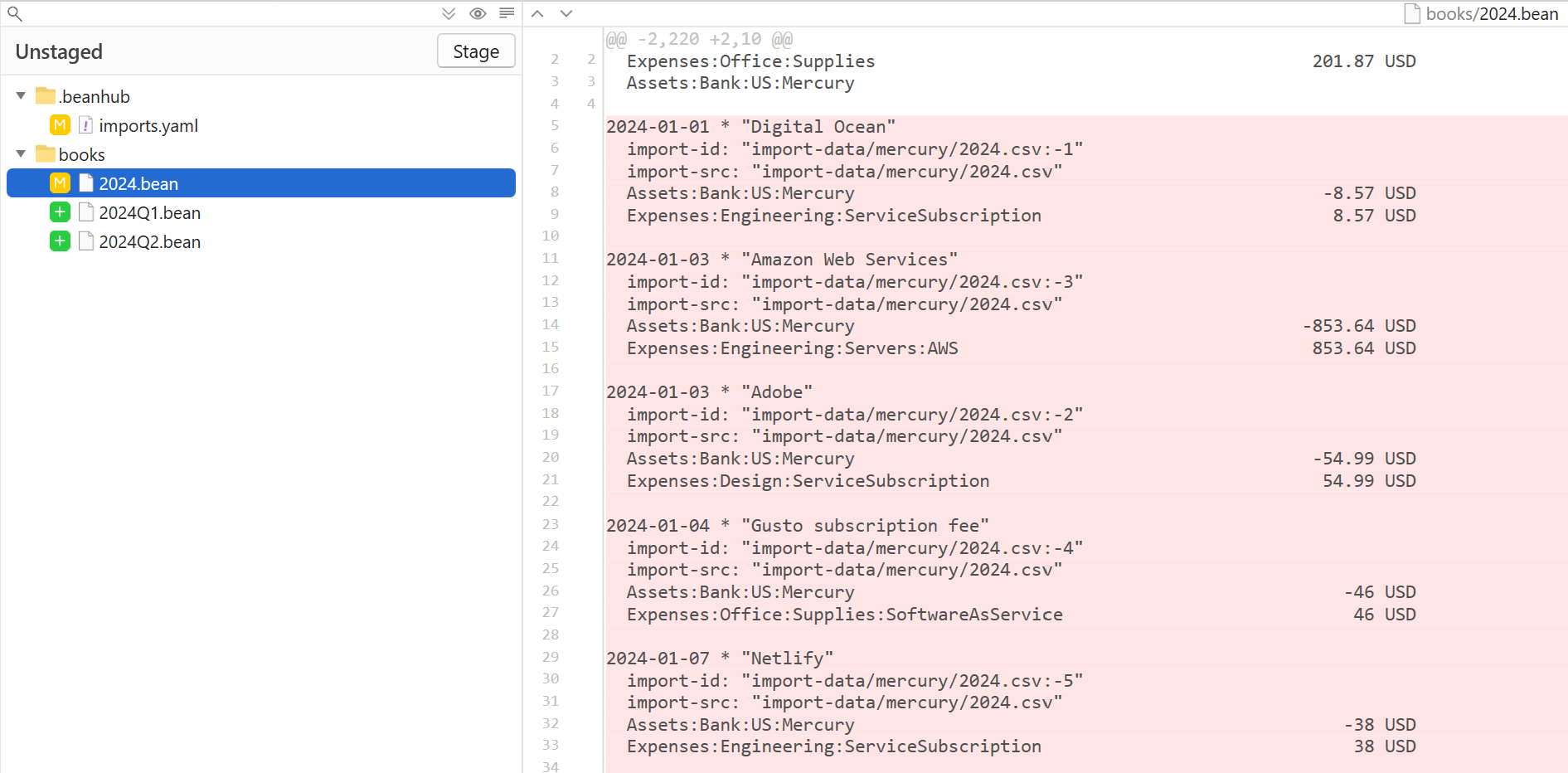
For example, change the import rules like this to output transactions to files grouped by quarter instead of year:
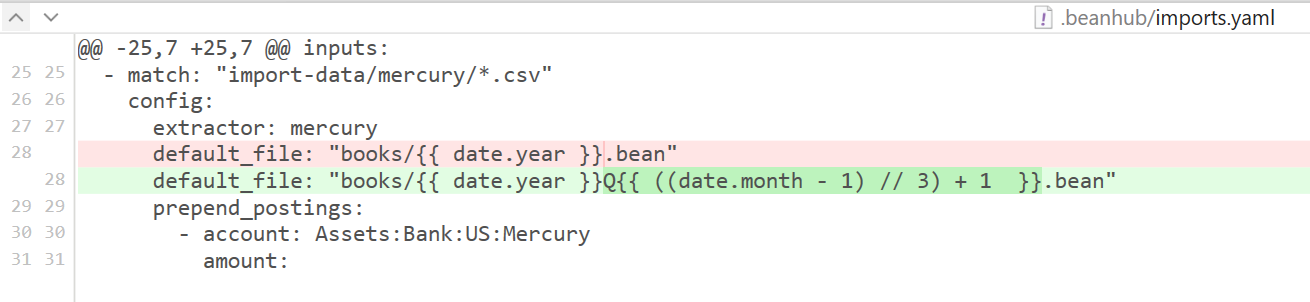
Then run the import again, and you will get this:
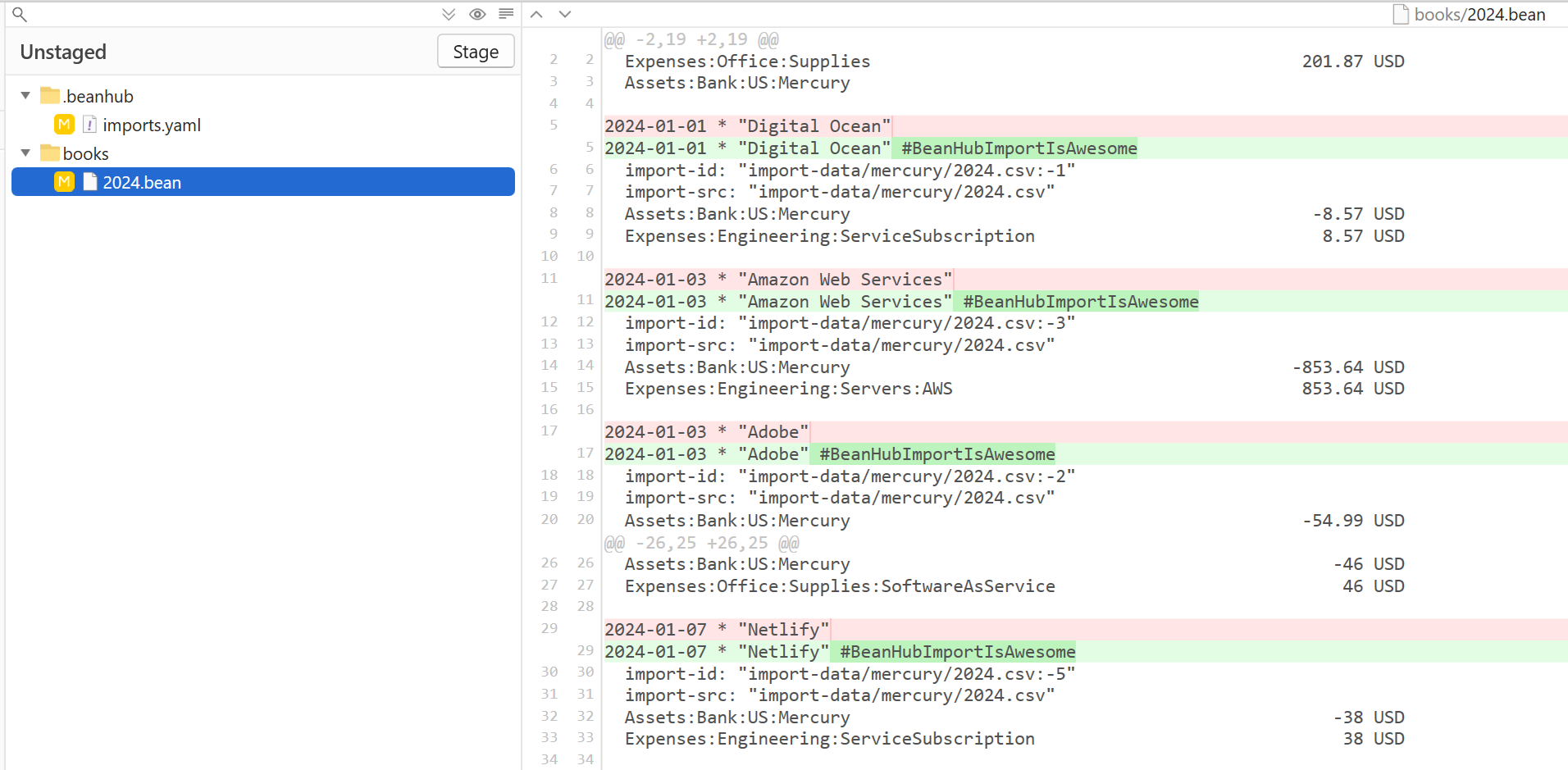
Another example is when you want to add new tags to the generated transactions, so you change the rules with new tags like this:
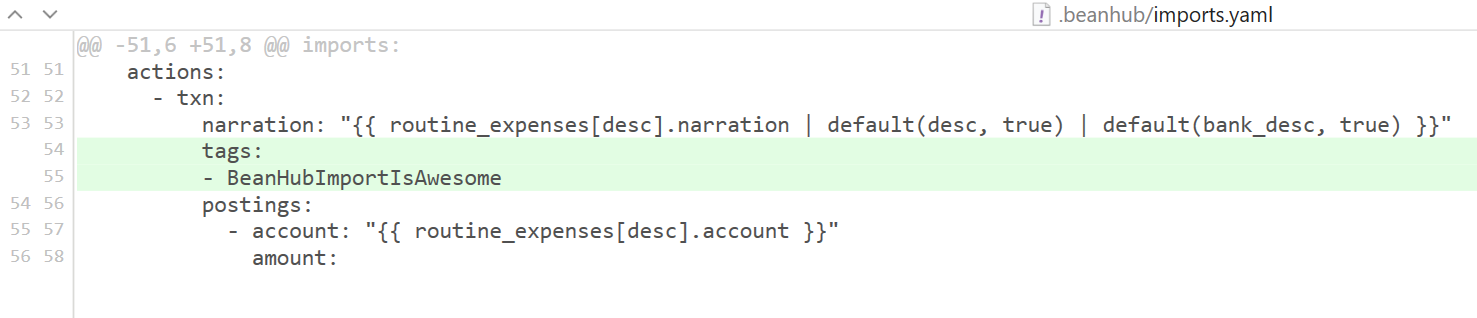
When you run import again, you will get this:
Please check out our demonstration repository beanhub-import-demo to try it yourself.
It's all declarative and idempotent. With beanhub-import, you say goodbye to manually importing and maintaining transactions! We hope you like this tool. It's still in the early stage of development. We are also working on making generating transactions from multiple sources possible. Please feel free to open issues in the repository if you have any feedback 🙌
Why?
There are countless Beancount importer projects out there, so why do we have to build a new one from the ground up? We are building a new one with a completely new design because we cannot find an importer that meets our requirements for BeanHub. There are a few critical problems we saw in the existing Beancount importers:
- Need to write Python code to make it work
- Doesn't handle duplication problem
- Hard to reuse because extracting logic is coupled with generating logic
- Hard to customize for our own needs
- Can only handle a single source file
Example
The rules of beanhub-import is defined in YAML format at .beanhub/imports.yaml. Here's an example
# the `context` defines global variables to be referenced in the Jinja2 template for
# generating transactions
context:
routine_expenses:
"Amazon Web Services":
account: Expenses:Engineering:Servers:AWS
Netlify:
account: Expenses:Engineering:ServiceSubscription
Mailchimp:
account: Expenses:Marketing:ServiceSubscription
Circleci:
account: Expenses:Engineering:ServiceSubscription
Adobe:
account: Expenses:Design:ServiceSubscription
Digital Ocean:
account: Expenses:Engineering:ServiceSubscription
Microsoft:
account: Expenses:Office:Supplies:SoftwareAsService
narration: "Microsoft 365 Apps for Business Subscription"
Mercury IO Cashback:
account: Expenses:CreditCardCashback
narration: "Mercury IO Cashback"
WeWork:
account: Expenses:Office
narration: "Virtual mailing address service fee from WeWork"
# the `inputs` defines which files to import, what type of beanhub-extract extractor to use,
# and other configurations, such as `prepend_postings` or default values for generating
# a transaction
inputs:
- match: "import-data/connect/{{ match_path }}"
config:
# use the extractor from loop variables for extracting transactions from the input file
extractor: "{{ extractor }}"
# the default output file to use
default_file: "books/{{ date.year }}.bean"
# postings to prepend for all transactions generated from this input file
prepend_postings:
# the `input_account` will be replaced with the variable value provided in the loop
- account: "{{ input_account }}"
amount:
number: "{{ amount }}"
currency: "{{ currency | default('USD', true) }}"
# extra attrs allows you to define extra attributes to pass down to import stage
extra_attrs:
input_method: "{{ input_method | default('auto') }}"
# extra attrs are rendered with txn attributes before processing import rules,
# so that you can also use attributes from the transaction, making it a very powerful
# way to define custom matching logic
high_amount_purchase: "{{ amount > 1000 }}"
# You can also set a simple value like str, bool, or number
tag_name: "my-value"
# filter allows you to consume only the transactions from input which meet certain conditions.
# For example, the example below consumes transactions only after 2024-01-01.
# This is particular useful when you have hand-crafted books in the past and you also have
# bank transactions in CSV input files from that period. To avoid duplication and only
# let beanhub-import generate transactions for you with the new transactions, you can add a filter
# like this.
filter:
- field: date
op: ">="
value: "2024-01-01"
# loop through different variables with the same input file template to avoid repeating
# the same input config over and over
loop:
- match_path: mercury/*.csv
input_account: Assets:Bank:US:Mercury
extractor: mercury
input_method: "manual"
- match_path: chase/*.csv
input_account: Liabilities:CreditCard:US:ChaseFreedom
extractor: chase_credit_card
# the `imports` defines the rules to match transactions extracted from the input files and
# how to generate the transaction
imports:
- name: Routine expenses
match:
extractor:
equals: "mercury"
desc:
one_of:
- Amazon Web Services
- Netlify
- Mailchimp
- Circleci
- WeWork
- Adobe
- Digital Ocean
- Microsoft
- Mercury IO Cashback
actions:
# generate a transaction into the beancount file
- file: "books/{{ date.year }}.bean"
txn:
narration: "{{ routine_expenses[desc].narration | default(desc, true) | default(bank_desc, true) }}"
postings:
- account: "{{ routine_expenses[desc].account }}"
amount:
number: "{{ -amount }}"
currency: "{{ currency | default('USD', true) }}"
# To avoid many match/actions statements for mostly identical transaction template,
# you can also define different match conditions and the corresponding variables for the transaction template
- name: Routine Wells Fargo expenses
# the condition shared between all the matches
common_cond:
extractor:
equals: "plaid"
file:
# You can also use named group to capture variables in the regular expression
# to be used in generating transactions, like the `filename` as shown in the
# regex expression
suffix: "(.+)/Wells Fargo/(?P<filename>.+).csv"
match:
- cond:
desc: "Comcast"
vars:
account: Expenses:Internet:Comcast
narration: "Comcast internet fee"
- cond:
desc: "PG&E"
vars:
account: Expenses:Gas:PGE
narration: "PG&E Gas"
- cond:
# This is the extra attribute value defined in `extra_attrs` under the input rules
# We can also use them as part of the matching conditions.
input_method:
equals: manual
vars:
account: Expenses:Others
narration: "Manual input"
actions:
# generate a transaction into the beancount file
- file: "books/{{ date.year }}.bean"
txn:
payee: "{{ payee | default(omit, true) }}"
narration: "{{ narration | default(desc, true) | default(bank_desc, true) }}"
postings:
- account: "{{ account }}"
amount:
number: "{{ -amount }}"
currency: "{{ currency | default('USD', true) }}"
- name: Receive payments from contracting client
match:
extractor:
equals: "mercury"
desc:
equals: Evil Corp
actions:
- txn:
narration: "Receive payment from Evil Corp"
postings:
- account: "Assets:AccountsReceivable:EvilCorpContracting"
amount:
number: "{{ -amount / 300 }}"
currency: "EVIL.WORK_HOUR"
price:
number: "300.0"
currency: "USD"
- name: Ignore unused entries
match:
extractor:
equals: "mercury"
desc:
one_of:
- Mercury Credit
- Mercury Checking xx1234
actions:
# ignore action is a special type of import rule action to tell the importer to ignore the
# transaction so that it won't show up in the "unprocessed" section in the import result
- type: ignore
Usage
This project is a library and not meant for end-users.
If you simply want to import transactions from CSV into their beancount files, please checkout the import command of beanhub-cli.
Sponsor
This open-source library is sponsored by BeanHub, a modern accounting app built on Beancount and Git. It supports automatically importing transactions from 12,000+ financial institutions in 17 countries to your Beancount book. Many awesome features make bookkeeping with Beancount much easier. If you enjoy the content, you can also try out BeanHub starting free.
