Unique import id for transactions extracted from the CSV files
The biggest challenge we face when designing this system is finding a way to deduplicate the imported transactions from CSV. Obviously, we need a way to tell which transactions were already imported into Beancount files so that we don't need to import them again. To make this happen, we introduce the concept of import-id. Each transaction extracted from CSV files should have a unique import ID for us to identify. In this way, we can process the existing Beancount files and find out which transactions have already been imported. We add a metadata item with the key import-id to the transaction. Here's an example.
2024-04-15 * "Circleci"
import-id: "<unique import id>"
Assets:Bank:US:MyBank -30.00 USD
Expenses:Engineering:ServiceSubscription 30.00 USD
The next question will then be: What should be the unique ID for identifying each transaction in the CSV files? If the CSV files come with an ID column that already has a unique value, we can surely use it. However, what if there's no such value in the file? As we observed, most CSV files exported from the bank come with rows ordered by date. The straightforward idea is to use filename + lineno as the id. The Jinja2 template would look like this.
Then with a transaction from row 123 in the file import-data/mybank/2024.csv should have an import ID like this.
As most of the bank transactions export CSV files have transactions come in sorted order by date, even if there are new transactions added and we export the CSV file for the same bank again and overwrite the existing file, there will only be new lines added at the bottom of the file. Like this:
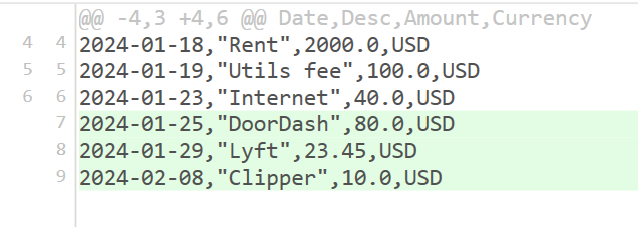
The line number of older transactions from the same CSV file with the same export time range and filter settings should remain the same. The file name and line number serve as a decent default unique identifier for the transactions from CSV files.
Although this approach works for most CSV files sorted by date in ascending order, it won't work for files in descending order.
For example, CSV files exported from Mercury came in descending order.
Obviously, any new transactions added to the export file will change the line number for all previously imported transactions.
To overcome the problem, we also provide reverse_lineno attribute in the extracted transaction.
It's the lineno - total_row_count value. As you may have noticed, we intentionally made the number negative.
It's trying to make it clear that this line (or row) number is in the reversed order, just like Python's negative index for accessing elements from the end.
With that, we can define the import ID for Mercury CSV files like this:
Since each CSV file may have its own unique best way to reliably identify a transaction, we add an optional default importer ID value to extractors in the beanhub-extract library as DEFAULT_IMPORT_ID.
Please note that these values are just default ones. Users can still override the default import ID Jinja2 template by setting the id value for their add_txn action in the import rule.